
Kanada merkezli yapay zeka şirketi Cohere, kurumsal LLM yarışında yeni amiral gemisi modelini duyurdu: Command A+. 20 Mayıs 2026’da Apache 2.0 lisansıyla açık kaynak olarak yayımlanan model, 218 milyar toplam parametre, 25 milyar aktif parametre ile Mixture of Experts (MoE) mimarisi üzerine kurulu. Cohere’in iddiası net: bu, şirketin şimdiye kadarki en hızlı ve en güçlü modeli — ve sadece iki H100 GPU veya tek bir Blackwell GPU üzerinde çalışabiliyor.
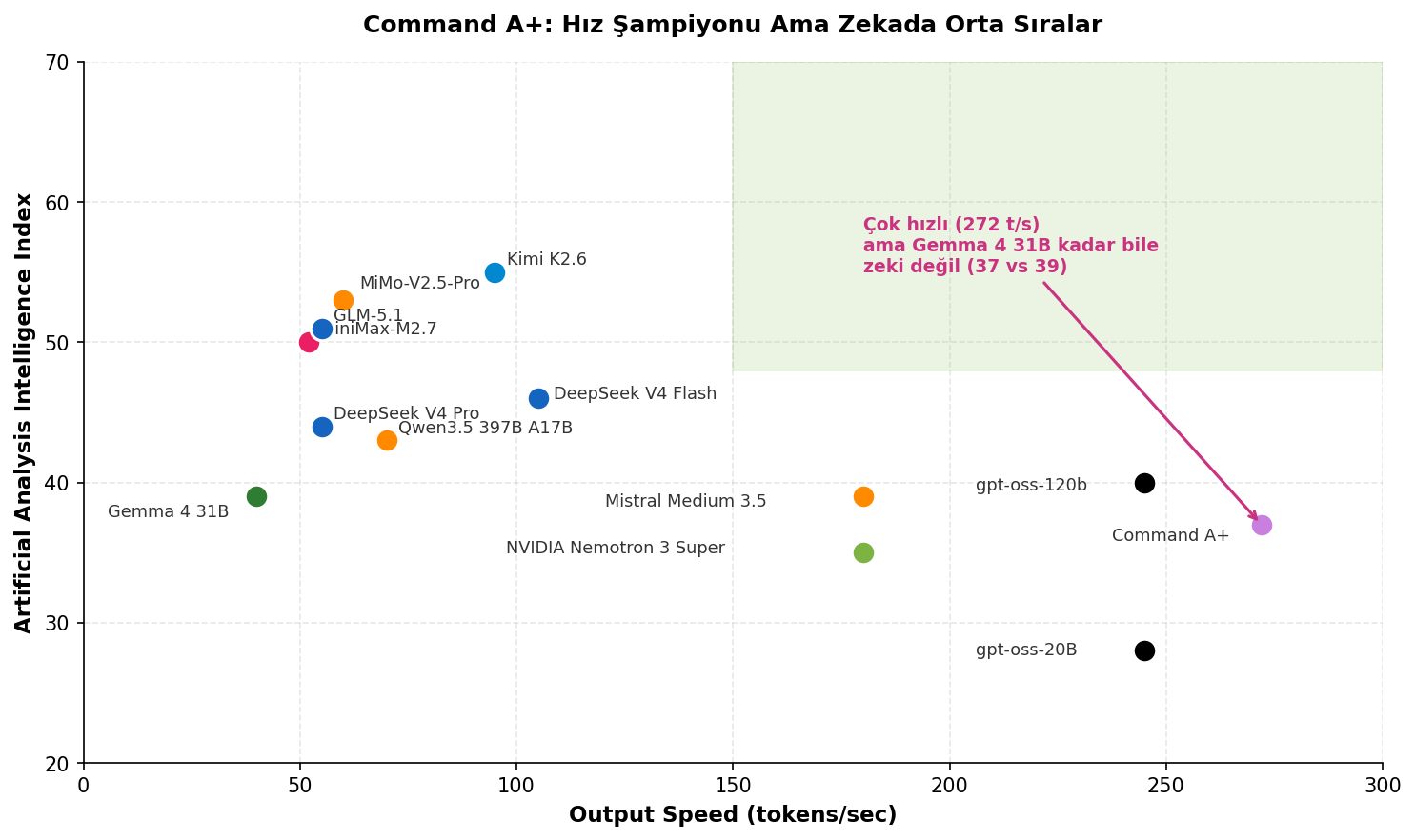
Ancak madalyonun bir de diğer yüzü var. Bağımsız değerlendirmelere göre Command A+’ın asıl ayırt edici özelliği hız — Artificial Analysis’in benchmark’larında saniyede 272 token ile açık ağırlıklı modeller arasında 1 numara. Buna karşılık zeka skoru tarafında Command A+, Gemma 4 31B kadar bile değil. Aşağıda detaylı bakacağız ama spoiler: Command A+ “kurumsal hızlı agent” senaryolarının modeli; “en zeki açık model” tahtı için değil.
“Sovereign AI” Felsefesi
Cohere’in son dönemdeki en belirgin pozisyonu “sovereign AI” (egemen yapay zeka) kavramı etrafında şekilleniyor. Şirket, OpenAI veya Anthropic gibi rakiplerinden farklı olarak, müşterilerin modelleri kendi altyapılarında çalıştırabilmesini, kontrol edebilmesini ve özelleştirebilmesini öne çıkarıyor.
Command A+ tam da bu vizyonun ürünü. Apache 2.0 lisansıyla açık kaynak yayımlanması, kurumsal kullanıcıların modeli kendi private cloud, on-premise veya regulated environment’larında çalıştırabilmesi anlamına geliyor. Cohere’in “AI independence for all” sloganı, özellikle ABD merkezli kapalı modellere bağımlılık endişesi taşıyan kurum ve devletler için doğrudan bir mesaj.
Teknik Özet
| Özellik | Command A+ |
|---|---|
| Mimari | Sparse / MoE |
| Boyut | 218B toplam, 25B aktif |
| Context | 128K input, 64K max generation |
| Input modalitesi | Metin, görsel, tool use |
| Output modalitesi | Metin, reasoning, tool use |
| Dil desteği | 48 dil |
| Lisans | Apache 2.0 |
| Çerçeve desteği | vLLM, Transformers |
| Minimum donanım | 1× B200 @W4A4 veya 2× H100 @W4A4 |
Bir Modelde Tüm Yetenekler
Command A+’ın en önemli pratik özelliği, önceki Command A ailesindeki ayrı modelleri tek bir modelde birleştirmesi. Önceden ihtiyacınıza göre Command A (genel amaçlı), Command A Reasoning (akıl yürütme), Command A Vision (görsel) veya Command A Translate (çeviri) modellerini ayrı ayrı dağıtmanız gerekirken, Command A+ hepsini bir araya getiriyor:
- Reasoning ✓
- Multimodal (görsel anlama) ✓
- Tool use ✓
- Multilingual ✓ (48 dil; eski versiyonlar 23 dildi)
Bu birleşim, kurumsal ortamlarda model orkestrasyon yükünü ciddi şekilde azaltıyor.
Açıkça Söyleyelim: Asıl Avantaj Hız, Zekada Geride
Cohere’in pazarlama mesajları “en güçlü model” diyor ama Artificial Analysis’in bağımsız Intelligence Index v4.0 değerlendirmesine baktığımızda tablo daha nüanslı:
| Model | Intelligence Index | Output Speed (t/s) |
|---|---|---|
| Kimi K2.6 | 55 | ~95 |
| MiMo-V2.5-Pro | 53 | ~60 |
| GLM-5.1 | 51 | ~55 |
| MiniMax M2.7 | 50 | ~52 |
| DeepSeek V4 Flash | 46 | ~105 |
| DeepSeek V4 Pro | 44 | ~55 |
| Qwen3.5 397B A17B | 43 | ~70 |
| gpt-oss-120b (high) | 40 | ~245 |
| Gemma 4 31B | 39 | ~40 |
| Mistral Medium 3.5 | 39 | ~180 |
| Command A+ | 37 | 272 |
Yani somut olarak: Command A+ saf zeka tarafında Gemma 4 31B’nin (39) bile altında ve birinci sıradaki Kimi K2.6’nın (55) çok gerisinde. Cohere’in “en güçlü model” ifadesi, kendi Command A ailesinin önceki sürümleriyle karşılaştırma içindir — açık ağırlıklı pazarın geneliyle değil.
Buna karşılık output hızında 272 token/saniye ile pazarın açık ara birincisi. Karşılaştırma için: Kimi K2.6 (~95), MiniMax M2.7 (~52), Gemma 4 31B (~40). Yani Command A+, en yakın rakibinden bile yaklaşık 2,8 kat daha hızlı.
Bu konumlama Cohere’in stratejisini doğruluyor: “en zeki” değil, “en hızlı kurumsal agent için pratik”. Vision + tool use + reasoning + 48 dil + 2 H100’de çalışabilme + 272 t/s. Bu paketin toplamı kurumsal agentic workflow’lar için ciddi anlam taşıyor; ancak saf reasoning gücüne ihtiyaç duyan use case’ler için başka modeller daha mantıklı.
Performans Sıçramaları
Command A+’ın önceki Command A Reasoning ile karşılaştırması bazı çarpıcı sonuçlar gösteriyor:
- 𝜏²-Bench Telecom: %37 → %85 (agentic conversation)
- Terminal-Bench Hard: %3 → %25 (agentic coding) — 8x’lik bir iyileşme
- MMMU: %75,1 (Command A Vision’da %65,3)
- MMMU Pro: %63
- MathVista: %73,5 → %80,6
- CharXiv reasoning: %46,9 → %52,7
Cohere’in kendi North platformundaki dahili değerlendirmelerde de güçlü artışlar var:
- Agentic Question Answering doğruluğu: %20 artış
- Spreadsheet analysis kalitesi: %32 artış
- Memory Usage Quality: %39 → %54
Artificial Analysis Intelligence Index’te 37 puanla, lider açık modeller arasında konumlanıyor.
Verimlilik: 218B Modeli 2 H100’de Çalıştırın
Modelin asıl çarpıcı tarafı verimlilik. Cohere, üç farklı quantizasyon seçeneği sunuyor:
- BF16 (16-bit) — Tam hassasiyet
- FP8 (8-bit) — Dengeli
- W4A4 (4-bit) — Maksimum verimlilik
Cohere’in iddiasına göre W4A4 quantizasyonunda kalite kaybı “fark edilemez seviyede”. Pratik sonuç: 218 milyar parametreli bir model sadece iki H100 GPU veya tek bir Blackwell B200 üzerinde çalışabiliyor. Bu, kurumsal dağıtım için devasa bir maliyet avantajı.
Hız: %63 Daha Fazla TOPS
Command A Reasoning (111B dense) ile aynı quantizasyon ve concurrency seviyelerinde karşılaştırıldığında Command A+:
- Output Tokens per Second (TOPS) tarafında %63’e kadar daha yüksek
- Time To First Token (TTFT) tarafında %17’ye kadar azalma
- W4A4 quantizasyonu ek olarak %47 daha fazla hız ve %13 daha az latency sağlıyor
Üstüne Cohere, MoE mimarisi için özel olarak optimize edilmiş speculative decoding kullanıyor; bu da hem metin hem multimodal girişler için ek 1,5-1,6x hızlanma sağlıyor.
Yeni Tokenizer ile %20 Sıkıştırma
Command A+, Cohere’in yeni tokenizer’ını kullanan ilk model. Bu, özellikle non-European dillerde önemli kazançlar getiriyor:
- Arapça: %20 daha verimli tokenization
- Korece: %16 daha verimli
- Japonca: %18 daha verimli
Daha az tokenla aynı cevabın üretilmesi, inference maliyetinin doğrudan düşmesi anlamına geliyor. Bu özellikle çok dilli kurumsal uygulamalar için kritik.
North Platformu ile Bütünleşme
Command A+’ın geliştirilmesinin arkasında Cohere’in North platformuyla geçen bir yıllık deneyim var. North, Cohere’in entegre kurumsal AI workspace’i; agentic AI inşa etmek ve dağıtmak için kullanılıyor. Command A+ buradaki gerçek üretim ihtiyaçlarına göre tasarlandı:
- Tek modelde tüm yetenekleri toplama (deployment basitliği)
- Lokal çalışabilirlik (sovereign AI gereksinimi)
- MCP-bağlı cloud file system’lar üzerinde reasoning
- Spreadsheet analizi
- Önceki oturumlardan hatırlama (memory)
Erişim ve Dağıtım
Model şu kanallar üzerinden erişilebilir:
- Hugging Face — üç farklı quantizasyon (BF16, FP8, W4A4) ile açık ağırlıklar
- Model Vault — Cohere’in managed inference platformu
- Hugging Face Spaces — ücretsiz demo
- Cohere API — geliştirici erişimi
Çerçeve tarafında vLLM ve Transformers ile day-one uyumluluk sağlanmış. vLLM’in son sürümleri zaten W4A4 quantizasyonunu destekliyor.
Fujitsu Açık Desteği
Lansmanda öne çıkan kurumsal destek Fujitsu’dan geldi. Şirketin CTO’su Vivek Mahajan açıklamasında, Command A+’ın MoE mimarisinin ve güçlü agentic performansının, Fujitsu’nun Takane ve Kozuchi Enterprise AI Factory üzerinden sunduğu sovereign AI çözümleriyle örtüştüğünü belirtti.
Karşılaştırmalı Konum: Açık Ağırlıklı Pazardaki Yer
Command A+, açık ağırlıklı modeller pazarında kendine özgün bir yer açıyor. En önemli karşılaştırmalar 200-300B sınıfındaki MoE modellerle yapılabilir:
| Model | Toplam / Aktif | Context | Multimodal | Diller | Lisans | Çıkış |
|---|---|---|---|---|---|---|
| Cohere Command A+ | 218B / 25B | 128K | ✓ Vision | 48 | Apache 2.0 | 20 May 2026 |
| MiniMax M2.7 | 230B / 10B | 200K | ✗ Text-only | — | — | 18 Mar 2026 |
| DeepSeek V4 Flash | 284B / 13B | 1M | ✗ Text-only | — | MIT | 24 Nis 2026 |
MiniMax M2.7 ile Karşılaştırma
MiniMax M2.7 ile Command A+ birbirine en yakın iki model. Toplam parametre sayıları yakın (230B vs 218B) ama Command A+’ın aktif parametresi 2,5 kat daha yüksek (25B vs 10B). Bu şu anlama geliyor: M2.7 token başına daha az hesaplama yapıyor ve daha ucuz çalışıyor; Command A+ ise token başına daha güçlü.
İkisinin de ayrıldığı kritik nokta multimodal yetenek. M2.7 yalnızca metin işliyor; Command A+ ise vision input destekliyor ve MMMU’da %75,1, MMMU Pro’da %63 puan alıyor. Kurumsal döküman işleme, faktura/sözleşme analizi, grafik/tablo reasoning’i gereken senaryolarda Command A+’ın avantajı çok büyük.
Performans tarafında M2.7 Artificial Analysis Intelligence Index’te 50 puanla daha yüksek; Command A+ ise 37 puanda. Yani saf “zeka skoru” tarafında M2.7 önde; ancak Command A+ kurumsal use case’lerde (özellikle MCP-bağlı agentic workflow’lar, multilingual deployment, multimodal döküman analizi) daha pratik bir paket sunuyor.
Fiyat tarafında M2.7’nin API fiyatlandırması $0,30 input / $1,20 output (1M token başına) — Command A+’a göre genelde daha ucuz. Ancak Command A+’ın asıl iddiası API fiyatından çok lokal/private dağıtım: 2 H100’de çalışabilmesi.
DeepSeek V4 Flash ile Karşılaştırma
DeepSeek V4 Flash da Command A+’a yakın bir sınıfta: 284B toplam, 13B aktif parametre, 1 milyon token bağlam. V4 Flash’ın en büyük avantajı 1M token context window, agresif fiyatlandırma ($0,14 input / $0,28 output) ve MIT lisansı. Reasoning gücü de yüksek (Intelligence Index’te 43).
Ancak burada da Command A+’ın iki belirgin avantajı var: multimodal yetenek ve 48 dil desteği. V4 Flash yalnızca metin işliyor. Çok dilli kurumsal pazarda (özellikle Avrupa, Orta Doğu, Asya iş yüklerinde) Command A+’ın tokenizer optimizasyonu da (Arapça %20, Korece %16, Japonca %18 daha verimli) ciddi maliyet farkı yaratıyor.
Karşılaştırmanın özeti şöyle: Sırf reasoning + uzun bağlam istiyorsanız DeepSeek V4 Flash. Sırf en ucuz inference için MiniMax M2.7. Multimodal + multilingual + kurumsal agentic dağıtım için Command A+.
Cohere’in stratejisi de rakiplerinden farklı: en zeki modeli kovalamak yerine, “gerçek kurumsal iş yüklerinde en pratik model” olmaya odaklanıyor. Kurumlar bir LLM’i ne kadar kolay kendi altyapılarına entegre edebilir, ne kadar düşük maliyetle çalıştırabilir ve regulated ortamlarda nasıl yönetebilir — Command A+ tam olarak bu soruları cevaplıyor.
Önümüzdeki Tehdit: MiniMax M3 Geliyor
Command A+’ın açık ağırlıklı pazardaki konumlanmasını test edecek en büyük yakın gelişme: MiniMax M3. Sektör kaynaklarına göre M3 Mayıs 2026 içinde duyurulacak. Manifold Markets piyasasında Haziran öncesi çıkış olasılığı %80 olarak fiyatlanıyor.
M3 hakkında dolaşan ön bilgilere göre:
- Mimari olarak ölçeklenmeye odaklı; muhtemelen M2.7’nin 230B toplamından daha büyük
- Agentic yeteneklerde ciddi atlama bekleniyor
- Kullanım odağı: “office scenarios” — yani kurumsal iş ortamı senaryoları
- “Jagged behavior” beklentisi (bazı görevlerde çok güçlü, bazılarında zayıf)
Bu, doğrudan Command A+’ın hedeflediği aynı pazar segmentine işaret ediyor: kurumsal agentic AI. Eğer M3 multimodal yetenek de eklerse, Cohere’in en büyük teknik avantajlarından biri (vision + tool use + reasoning tek modelde) zayıflayabilir. Multimodal eklenmezse Command A+’ın bu segmentteki konumu sağlam kalır.
Önümüzdeki haftalarda M3’ün resmi spec’leri ve benchmark sonuçları çıktıkça, Command A+’ın gerçek rekabetçiliğini daha net görmek mümkün olacak. Şu anki konumu itibarıyla Cohere, açık ağırlıklı kurumsal AI yarışında pazara çok güçlü bir kart koydu; ancak yarış kızışıyor.
Sonuç
Command A+, açık ağırlıklı LLM ekosisteminde önemli ama nüanslı bir konumlama. Trilyon parametreli model yarışına katılmıyor; “en zeki açık model” tahtını da hedeflemiyor. Bunun yerine “kurumsal dağıtım için optimum verimlilik + tüm yetenekleri tek modelde toplama + sektör lideri output hızı” denklemini hedefliyor.
Eğer saf reasoning gücü arıyorsanız Kimi K2.6 (55), MiMo-V2.5-Pro (53) veya MiniMax M2.7 (50) daha mantıklı. Ama hızlı, multimodal, çok dilli, agentic ve sovereign deployment yapabileceğiniz tek model arıyorsanız Command A+ pazardaki en pratik seçeneklerden biri.
Özellikle aşağıdaki kullanım senaryoları için Command A+ ciddi bir seçenek:
- On-premise kurumsal AI dağıtımları (finansal hizmetler, sağlık, kamu)
- Çok dilli müşteri operasyonları (48 dil desteği)
- Sovereign cloud zorunluluğu olan kurumlar (Apache 2.0 + lokal çalışabilirlik)
- Tool use ve RAG ağırlıklı agentic uygulamalar
- Çoklu modaliteye ihtiyaç duyan döküman işleme akışları
Önümüzdeki dönemde özellikle North platformuyla entegre kullanım, Cohere’in kurumsal segmentteki konumunu daha da güçlendirebilir. Açık ağırlıklı, MoE tabanlı, tek modelde her şeyi sunan yaklaşım, bu pazarda yeni bir standart oluşturuyor olabilir.
Bir yanıt yazın